前言
项目上有一个 AI合同审核助手 的需求,合同文档很不规范,没有固定的格式【我也不清楚为什么合同格式不固定,反正就是要借助LLM的能力来提取相关的信息】
自己写了一个LLM提取,很粗暴地分段直接扔到大模型中,但是发现文档上下文太长了,自己写地文章语义截断很难受,效果不是很好,写的提示词案例也不是很好,后面找到了一个 **Google开源 **的工具
langextract
项目地址
上手
我使用的是 Azure OpenAI 的 API
需要下载 langextract-litellm 插件来配合
pip install langextract-litellm
创建一个 .env 文件
AZURE_API_KEY=""
AZURE_API_BASE=""
AZURE_API_VERSION=""
把 API 填写进去即可
案例
import langextract as lx
import textwrap
# 定义抽取规则
prompt = textwrap.dedent("""\
按照出现顺序抽取合同文本中的主体、合同要素、权利义务和潜在风险点。
抽取时请使用原文,不要意译或合并实体。
每个实体请补充有意义的属性以增加上下文信息。
""")
# 以合同为案例
examples = [
lx.data.ExampleData(
text="甲方(北京某科技有限公司)与乙方(上海某贸易公司)签订软件采购合同,合同期限为两年。甲方应在收到发票后30日内支付合同款项。若乙方未能按期交付,需承担违约责任。",
extractions=[
lx.data.Extraction(
extraction_class="主体",
extraction_text="甲方(北京某科技有限公司)",
attributes={"角色": "购买方"}
),
lx.data.Extraction(
extraction_class="主体",
extraction_text="乙方(上海某贸易公司)",
attributes={"角色": "供应方"}
),
lx.data.Extraction(
extraction_class="合同要素",
extraction_text="合同期限为两年",
attributes={"要素": "期限", "数值": "两年"}
),
lx.data.Extraction(
extraction_class="权利义务",
extraction_text="甲方应在收到发票后30日内支付合同款项",
attributes={"义务主体": "甲方", "义务类型": "付款"}
),
lx.data.Extraction(
extraction_class="风险点",
extraction_text="若乙方未能按期交付,需承担违约责任",
attributes={"风险类型": "交付延误", "责任": "乙方承担违约责任"}
),
]
)
]
input_text = (
"甲方(广州华星科技有限公司)与乙方(深圳智远软件有限公司)签订本合同,"
"合同标的为企业管理软件的开发与交付,合同金额人民币200万元。"
"乙方应在2025年12月31日前完成软件交付。"
"若甲方未能按时付款,乙方有权暂停交付。"
"若任何一方严重违约,另一方有权单方解除合同。"
)
# Create model configuration
config = lx.factory.ModelConfig(
model_id="litellm/azure/gpt-4o",
provider="LiteLLMLanguageModel",
)
model = lx.factory.create_model(config)
# Extract entities
result = lx.extract(
text_or_documents=input_text,
model=model,
prompt_description=prompt,
examples=examples,
use_schema_constraints=False, # 已经有
prompt_validation_strict=False, # 不严格校验
)
print("✅ Extraction successful!")
print(f"Results: {result}")
# Save the results to a JSONL file
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# Generate the visualization from the file
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w", encoding="utf-8") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data)
else:
f.write(html_content)
with open("output.txt", "w", encoding="utf-8") as f:
f.write(str(result))
运行的结果:
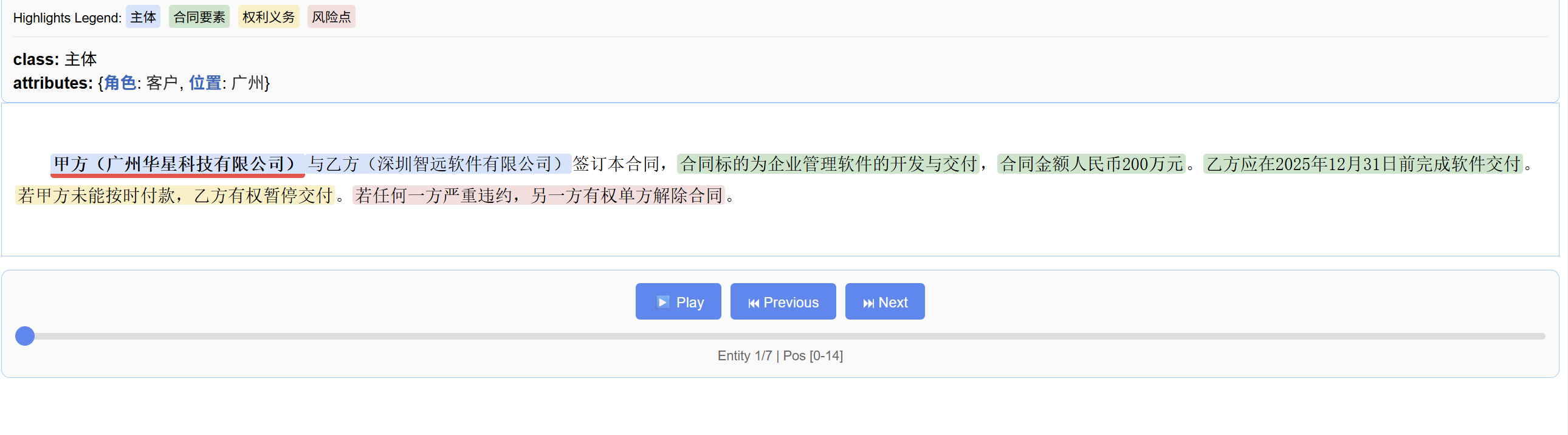
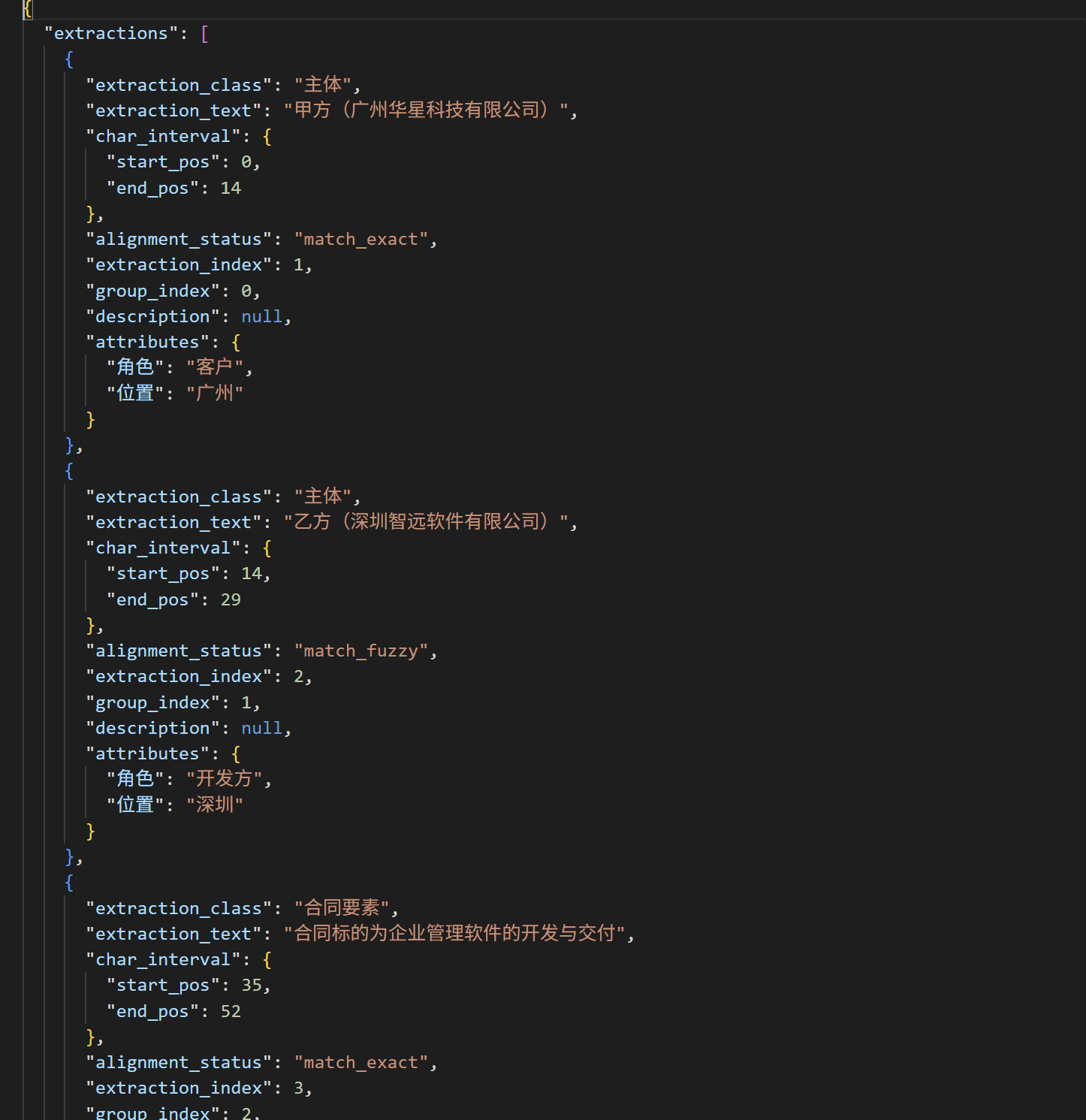
json 数据基本呈现这样,这样的数据
稍加修改
我觉得也可以自己写插件
修改分词逻辑
官方生成的 html 页面是不支持中文分词的,需要我们修改一下源码才能生成中文文本下的页面
位置在 langextract.core.tokenizer.py 里面的 正则表达式部分 148-155 这个部分
建议直接加到155后面并加上注释
\# 英文字母
_LETTERS_PATTERN = r"[A-Za-z]+"
\# 汉字(常用区间)
_CHINESE_PATTERN = r"[\u4e00-\u9fff]+"
\# 数字
_DIGITS_PATTERN = r"[0-9]+"
\# 符号(非字母数字空格汉字)
_SYMBOLS_PATTERN = r"[^A-Za-z0-9\u4e00-\u9fff\s]+"
\# 句子结束
_END_OF_SENTENCE_PATTERN = re.compile(r"[.?!。?!]$")
\# 带斜杠缩写
_SLASH_ABBREV_PATTERN = r"[A-Za-z0-9]+(?:/[A-Za-z0-9]+)+"
\# Token 模式:先匹配斜杠缩写,再匹配中文、英文、数字、符号
_TOKEN_PATTERN = re.compile(
rf"{_SLASH_ABBREV_PATTERN}|{_CHINESE_PATTERN}|{_LETTERS_PATTERN}|{_DIGITS_PATTERN}|{_SYMBOLS_PATTERN}"
)
实战方案
我们系统拿到的合同大多数是 PDF扫描版
这个时候需要我们使用OCR工具来先识别再抽取
我想到了一个让 微软 和 谷歌 联手的方案
markitdown 识别
langextract 提取
使用markitdown 对文章markdown化再用langextract 提取
.pdf —————————> .md —————————————–> .json
markitdown langextract
其实纯文本OCR我自己写的简单粗暴的工具也挺有意思的,效果也还行,只是后面得知LLM无法感知文章排版,所以就转为markdown格式了